네부캠 그룹프로젝트 - 6. 부하 테스트(Feat. Index, Clustering)
date
Dec 28, 2022
thumbnail
slug
naver-camp-project6
author
status
Published
tags
Project
summary
K6를 이용한 API 부하 테스트 및 환경에 따른 성능 비교
type
Post
updatedAt
Jan 23, 2023 03:43 PM
1️⃣ 테스트 환경왜 서버가 아니라 로컬에서 테스트하나?2️⃣ 더미 데이터 삽입3️⃣ 테스트 도구4️⃣ Grafana K6 테스트용 스크립트5️⃣ 테스트 결과가상 유저 1000명 / index 설정 X / node 클러스터링 X가상 유저 1000명 / index 설정 O / node 클러스터링 X가상 유저 1000명 / index 설정 O / node 클러스터링 O6️⃣ 테스트 결과 정리7️⃣ 결론
이전에 MongoDB에 인덱스를 적용하고, 인덱스를 타는지만 확인하고, 실제 성능에 대한 테스트는 측정해보지 않았다.따라서 아래와 같은 상황의 부하를 테스트해보려 한다.
- 가상 유저 1000명 / 30초의 부하 / index 설정 X / node 클러스터링 X
- 가상 유저 1000명 / 30초의 부하 / index 설정 O / node 클러스터링 X
- 가상 유저 1000명 / 30초의 부하 / index 설정 O / node 클러스터링 O
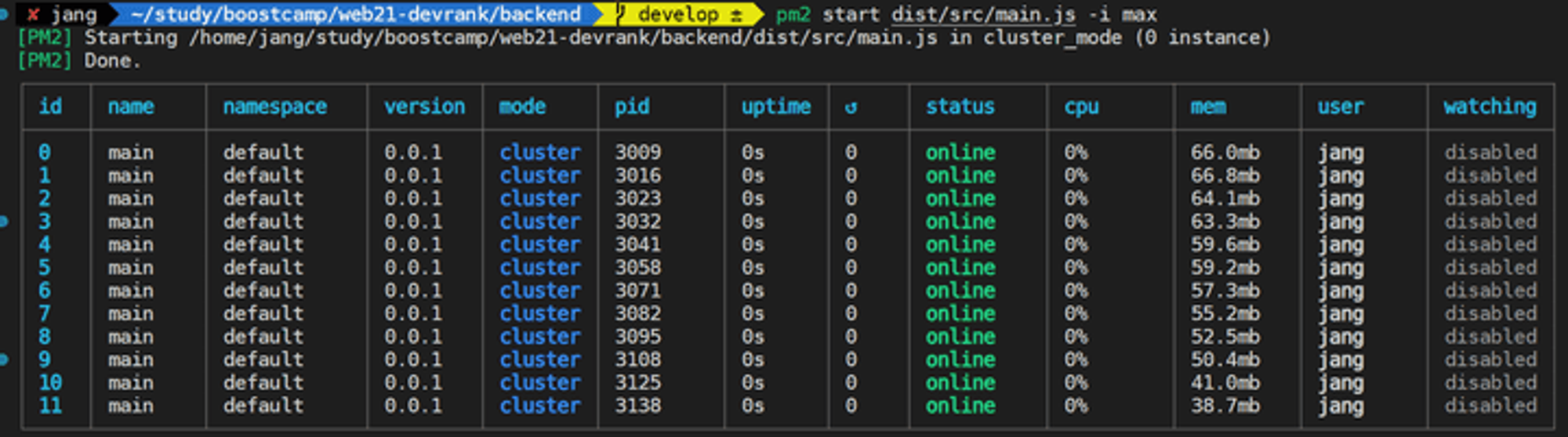
PM2를 통한 클러스터링 환경까지 테스트 하는 이유는 싱글 스레드 기반의 Node.js는 멀티 코어 환경에서 클러스터링이 필수적이기 때문이다. 그 이유는 이전에 아래 두 글에 작성했었다. 따라서 이유가 궁금한 사람은 아래 글들을 참고하기 바란다.
시행착오가 있었는데, MongoDB Atlas에 10만개의 데이터를 그냥 넣고 부하 테스트를 진행하니, DB가 마비되는 상황이 발생했다.(P-S-S replica set으로 구성되어 있는데도 말이다…)
예상 되는 원인은 다음과 같다.
- MongoDB Atlas 무료 버전의 버퍼 공간(RAM)과 vCPU가 너무 적음
- 데이터가 10만개가 됨에 따라 index의 크기가 너무 비대해져서 비효율적
- rankings API에 기본적으로 sort연산이 포함되어 있어 다른 쿼리보다 무거움
1️⃣ 테스트 환경
로컬 테스트 환경은 아래와 같다.
- CPU : AMD Ryzen 5 5600H (3.30 GHz) - 6코어 12스레드
- RAM : 16GB
- 샤드 수 : 3개
왜 서버가 아니라 로컬에서 테스트하나?
사실 클라우드에 있는 인스턴스에서 테스트해야 하나, migration할 시간적인 여유가 지금 없어서 로컬에서 테스트하였다.
이유는 현재 서비스가 MongoDB Atlas 무료 버전을 사용하고 있는데, 무료 버전에서는
샤딩같은 기능을 지원하지 않는다.따라서 대규모 데이터에서 테스트가 용이하지 않았다.그래서 일단 로컬 MongoDB에 샤딩을 적용한 후, 10만개의 데이터를 넣어서 index를 잘 타는지, 그에 따른 성능이 어떤지 내 로컬 환경에서 테스트를 진행하고, 추후 시간적인 여유가 충분할 때 MongoDB Atlas를 걷어내고 직접 설치해서 사용하려 한다.
결론적으로 인덱스에 대한 내 지적 호기심을 채우기 위한 테스트가 되는 것 같아서 조금 아쉽다.
2️⃣ 더미 데이터 삽입
아래와 같이 faker.js를 이용하여 10만개의 더미 유저 데이터를 생성하여 MongoDB에 삽입하였다.
function createRandomUser(): UserDto {
const fakerUsername = faker.internet.userName();
const score = faker.datatype.number(7000);
const fakeUser: UserDto = {
id: faker.datatype.uuid(),
username: fakerUsername,
lowerUsername: fakerUsername.toLowerCase(),
email: faker.internet.email(),
avatarUrl: faker.image.avatar(),
following: faker.datatype.number(200),
followers: faker.datatype.number(200),
score: score,
tier: getTier(score),
};
return fakeUser;
}3️⃣ 테스트 도구
부하 테스트 도구로는 사용이 제일 간편하다고 느낀 Grafana k6를 사용하려 한다. 이유는 아래와 같다.
- 도커 컨테이너로 실행이 가능하므로 따로 설치가 필요 없다.
- 무엇보다 javascript로 테스트용 스크립트를 작성할 수 있다.
- CLI 환경으로 큰 설정 없이 바로 사용하기 편리하다.
4️⃣ Grafana K6 테스트용 스크립트
아래와 같이 테스트용 스크립트를 작성하였다.
데이터가 10만개이기 때문에, 기본 10개 단위로 페이지네이션되므로 10000까지의 수를 랜덤하게 뽑아서 페이지로 사용하였다.다른 API보다 rankings API가 제일 무거운 연산을 갖는 API이므로, 해당 API만 테스트한다.
import http from "k6/http";
export const options = {
vus: 1000, // 가상 유저 수
duration: "30s", // 테스트 시간
};
export default function () {
// 데이터가 10만개이기 때문에, 기본 10개 단위로 페이지네이션되므로 10000까지의 수를 랜덤하게 뽑아서 페이지로 사용
const url = `http://xxx.xxx.xxx.xxx:3001/users/rankings?page=${Math.floor(Math.random() * 10000)}`;
const params = {
headers: {
"Content-Type": "application/json",
},
};
http.get(url, params);
}5️⃣ 테스트 결과
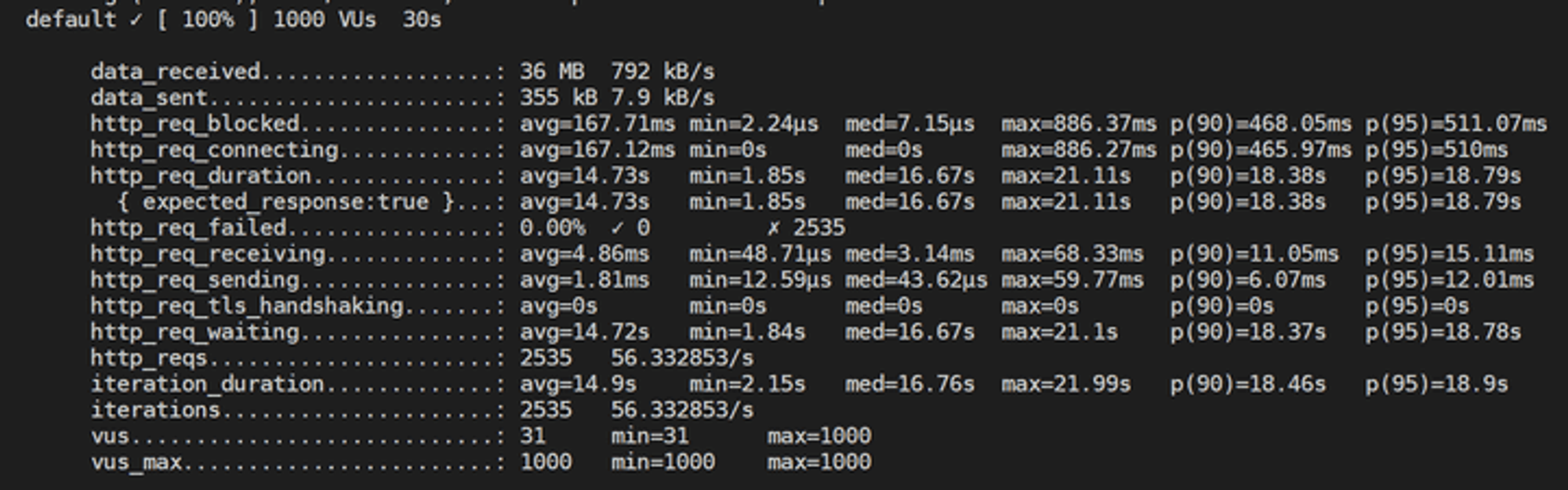
가상 유저 1000명 / index 설정 X / node 클러스터링 X
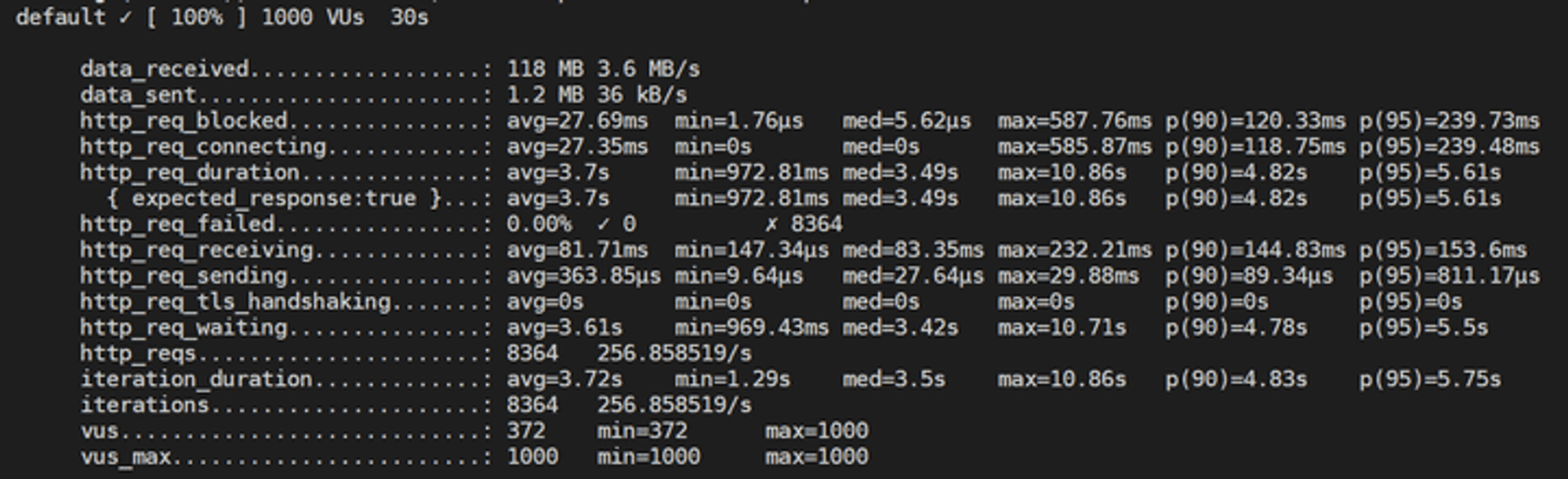
가상 유저 1000명 / index 설정 O / node 클러스터링 X
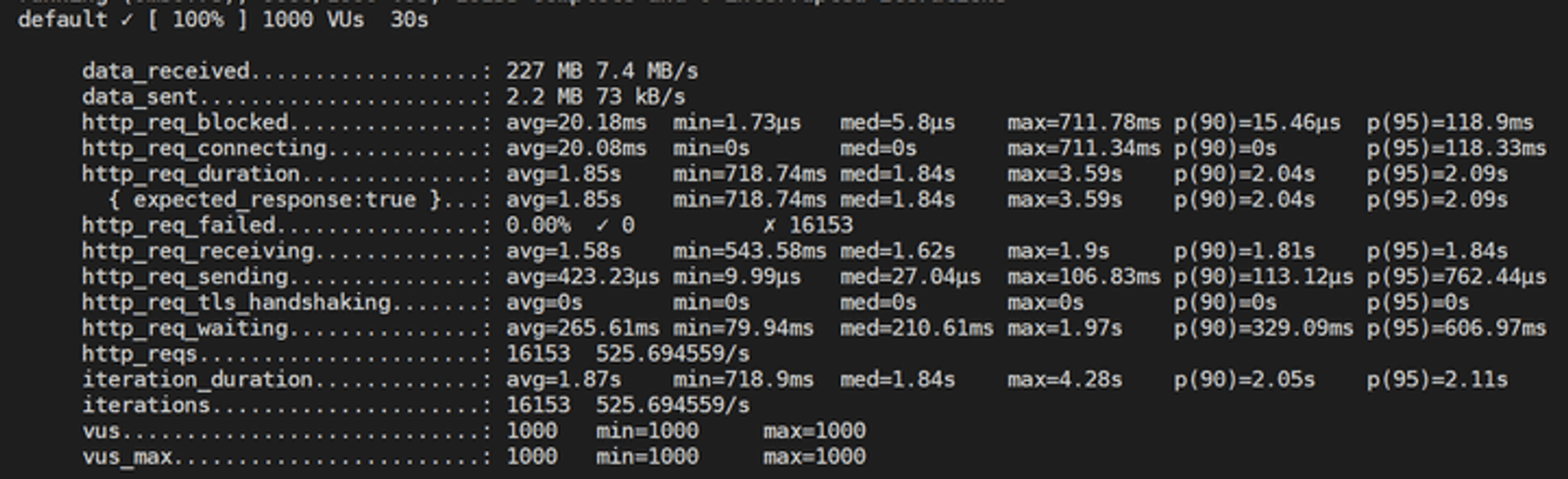
가상 유저 1000명 / index 설정 O / node 클러스터링 O
6️⃣ 테스트 결과 정리
테스트 결과에 보이는 필드는 많지만, 요청의 총 시간을 나타내는
http_req_duration만 봐도 될 듯 하다.이 값은
http_req_sending + http_req_waiting + http_req_receiving로 초기 DNS 조회/연결 시간 없이 원격 서버가 요청을 처리하고 응답하는 데 소요된 시간이다.항목 | index X | index O | index O + clustering |
처리한 요청 수 | 2535개 | 8364개 | 16153개 |
http_req_duration | 14.73s | 3.7s | 1.85s |
7️⃣ 결론
드라마틱한 테스트 결과를 보고 싶어서 데이터를 10만개, 가상 유저를 1000명을 설정하였다.
사실 우리 서비스에 1000명의 유저가 이렇게 빠른 속도로 API 콜을 할 가능성은 아주 먼 미래여도 희박할 듯 하다… 따라서 일단 실제 서버의 환경을 이렇게 구성해도 안전하지 싶다.
- 적절히 index를 설정함으로써, 조회 시 엄청난 성능 향상이 있음을 확인할 수 있었다.
- 추가적으로 node.js의 특성 상 clustering이 필요하고, 그에 따른 성능 향상도 직접 볼 수 있었다.
이처럼 index같은 DB적인 지식 뿐 아니라, 자신이 사용하는 언어의 특성도 잘 고려해야 좋은 개발자가 될 수 있을 것 같다.